Peer Reviewed Studies on the Differences Between the Sexes
Abstract
As part of an initiative to improve rigor and reproducibility in biomedical inquiry, the U.S. National Institutes of Health now requires the consideration of sex as a biological variable in preclinical studies. This new policy has been interpreted by some as a call to compare males and females with each other. Researchers testing for sex activity differences may not be trained to do and then, however, increasing risk for misinterpretation of results. Using a listing of recently published articles curated by Woitowich et al. (eLife, 2020; ix:e56344), we examined reports of sex differences and non-differences across ix biological disciplines. Sex differences were claimed in the majority of the 147 articles we analyzed; however, statistical evidence supporting those differences was often missing. For example, when a sex-specific effect of a manipulation was claimed, authors usually had not tested statistically whether females and males responded differently. Thus, sex-specific effects may be over-reported. In dissimilarity, we also encountered practices that could mask sex differences, such as pooling the sexes without first testing for a difference. Our findings support the demand for continuing efforts to railroad train researchers how to test for and written report sexual practice differences in order to promote rigor and reproducibility in biomedical research.
eLife assimilate
Biomedical research has a long history of including only men or male laboratory animals in studies. To address this disparity, the U.s. National Institutes of Health (NIH) rolled out a policy in 2016 called Sex activity as a Biological Variable (or SABV). The policy requires researchers funded past the NIH to include males and females in every experiment unless there is a potent justification not to, such as studies of ovarian cancer. Since then, the number of enquiry papers including both sexes has continued to grow.
Although the NIH does not require investigators to compare males and females, many researchers take interpreted the SABV policy as a call to do so. This has led to reports of sex differences that would otherwise have been unrecognized or ignored. However, researchers may not be trained on how best to test for sex differences in their data, and if the data are not analyzed appropriately this may lead to misleading interpretations.
Here, Garcia-Sifuentes and Maney have examined the methods of 147 papers published in 2019 that included both males and females. They discovered that more than half of these studies had reported sex differences, simply these claims were not always backed by statistical evidence. Indeed, in a large majority (more than seventy%) of the papers describing differences in how males and females responded to a treatment, the affect of the treatment was non actually statistically compared between the sexes. This suggests that sex-specific effects may exist over-reported. In contrast, Garcia-Sifuentes and Maney likewise encountered instances where an consequence may accept been masked due to data from males and females beingness pooled together without testing for a divergence first.
These findings reveal how easy it is to describe misleading conclusions from sexual practice-based information. Garcia-Sifuentes and Maney hope their work raises awareness of this outcome and encourages the development of more training materials for researchers.
Introduction
Historically, biomedical inquiry has non considered sex as a biological variable (SABV). Including only one sex in preclinical studies—or not reporting sexual activity at all—is a widespread issue (Sugimoto et al., 2019). In a cantankerous-disciplinary, quantitative cess of the 2009 biomedical literature, Beery and Zucker, 2011, found a apropos bias toward the use of males only. Equally awareness of this effect increased, in 2016 the National Institutes of Health (NIH) implemented a policy requiring consideration of SABV in the design, analysis, and reporting of all NIH-funded preclinical research (NIH, 2015; Clayton, 2018). Past addressing the long-standing over-representation of male non-human animals and cells, the policy was intended non only to ameliorate wellness inequities but to better rigor and reproducibility in biomedical inquiry (Clayton and Collins, 2014). Since 2016, NIH has fabricated bachelor a number of resource, including training modules, administrative funding supplements, and a middle program focused on sexual practice differences (Arnegard et al., 2020). These efforts accept resulted in the discovery of new sex differences across a wide spectrum of research fields (Arnegard et al., 2020).
Although the NIH policy does non explicitly crave that males and females exist compared directly with each other, the fact that more NIH-funded researchers must now study both sexes should pb to an increase in the frequency of such comparisons (Maney, 2016). For instance, at that place should be more testing for sex-specific responses to experimental treatments. Nevertheless, in a follow-upward to Beery and Zucker, 2011, written report, Woitowich et al., 2020, showed evidence to the contrary. Their analysis revealed that between 2011 and 2019, although the proportion of manufactures that included both sexes significantly increased (see also Will et al., 2017), the proportion that treated sex as a variable did non. This finding contrasts sharply with expectations, given not only the NIH mandate but also numerous calls over the past decade to disaggregate all preclinical data by sex and to examination for sexual practice differences (eastward.g., Becker et al., 2016; Potluri et al., 2017; Shansky and Tater, 2021; Tannenbaum et al., 2019; Woitowich and Woodruff, 2019).
Ane potential barrier to SABV implementation is a lack of relevant resources; for example, non all researchers have received grooming in experimental blueprint and data analysis that would allow them to test for sex differences using advisable statistical approaches. This bulwark is quite important not only because it prevents rigorous consideration of sex activity in the beginning place, but also because whatsoever less-than-rigorous test for sexual activity differences creates hazard for misinterpretation of results and dissemination of misinformation to other scientists and to the public (Maney, 2016). In other words, simply calling for the sexes to be compared is not enough if researchers are non trained to do so; if SABV is implemented haphazardly, information technology has the potential to subtract, rather than increase, rigor and reproducibility.
In this study, our goal was to analyze recently published articles to determine how often sexual practice differences are existence reported and what statistical testify is most oftentimes used to support findings of divergence. To conduct this assessment, nosotros leveraged the drove of articles originally curated by Woitowich et al., 2020, for their analysis of the extent to which SABV is existence implemented. Their original list, which was itself generated using criteria adult by Beery and Zucker, 2011, included 720 manufactures published in 2019 in 34 scholarly journals within nine biological disciplines. Of those, Woitowich et al. identified 151 manufactures that included females and males and that analyzed data disaggregated past sex or with sex as fixed factor or covariate. Working with that listing of 151 articles, we asked the following questions for each: Showtime, was a sex difference reported? If so, what statistical approaches were used to back up the merits? Nosotros focused in detail on studies with factorial designs in which the authors reported that the effect of one factor, for instance treatment, depended on sex. Next, nosotros asked whether information from males and females were kept divide throughout the article, and if they were pooled, whether the authors tested for a sexual practice difference before pooling. Finally, we noted whether the authors used the term 'sexual activity' or 'gender', especially in the context of preclinical (non-human creature) studies.
Results
We began with 151 articles, published in 2019, that were determined past Woitowich et al., 2020, to have (ane) included both males and females and (2) reported data past sex (disaggregated or with sex included in the statistical model). Of those, we identified 4 that independent data from only one sex (e.chiliad., animals of the other sex had been used only as stimulus animals or to calculate sexual practice ratios). Afterward excluding those articles, our final sample size was 147. Run into Table 1 for the sample sizes of manufactures from each discipline. More one-third of the studies were on humans (35%) and a similarly large proportion on rats or mice (31%). The remainder encompassed a broad variety of species including non-man primates, dogs, cats, pigs, sheep, deer, squirrels, racoons, Tasmanian devils, lemur, lions, meerkats, and mongoose. The codes are given in Supplementary file 1a, and results of coding are given in Supplementary file 1b (individual articles) and Supplementary file 1C (tabulated information).
Journals surveyed by discipline.
The categorization of journals into disciplines was every bit defined past Beery and Zucker, 2011, and Woitowich et al., 2020.
| Discipline | Journal 1 | Periodical 2 | Journal 3 | Journal 4 | No.articles |
|---|---|---|---|---|---|
| Beliefs | Behavioral Environmental and Sociobiology | Animate being Behavior | Animal Cognition | Behavioral Ecology | 40 |
| Behavioral Physiology | Journal of Comparative Psychology | Behavioral Neuroscience | Physiology and Behavior | Hormones and Behavior | xx |
| Endocrinology | European Periodical of Endocrinology | Journal of Neuroendocrinology | Endocrinology | American Journal of Physiology – Endocrinology and Metabolism | 27 |
| General Biology | PLoS Biology | Proceedings of the Royal Order B: Biological Sciences | Nature | Scientific discipline | 9 |
| Immunology | Journal of Immunology | Infection and Immunity | Amnesty | Vaccine | 10 |
| Neuroscience | Journal of Neuroscience | Neuroscience | Periodical of Comparative Neurology | Nature Neuroscience | ix |
| Pharmacology | Neuropsychopharmacology | Journal of Psychopharmacology | Journal of Pharmacology and Experimental Therapeutics | British Journal of Pharmacology | 11 |
| Physiology | Journal of Physiology (London) | American Journal of Physiology – Renal Physiology | American Periodical of Physiology – Gastrointestinal and Liver Physiology | American Periodical of Physiology – Heart and Circulatory Physiology | 12 |
| Reproduction | Biology of Reproduction | Reproduction | ix |
Question ane: Was a sex difference reported?
Results pertaining to Question 1 are shown in Figure 1A. Comparing the sexes, either statistically or past assertion, was common, occurring in eighty% of the articles. A positive finding of a sex deviation was reported in 83 articles, or 57%. Of the articles reporting a sex departure, 41 (49% of the 83 articles) mentioned that result in the title or the abstruse. Thus, in our sample of articles in which data were reported past sexual practice, a sex difference was reported in more than half of the manufactures and in half of those, the departure was treated as a major finding past highlighting it in the title or abstract. In 44% of articles, a sex difference was neither stated nor implied.
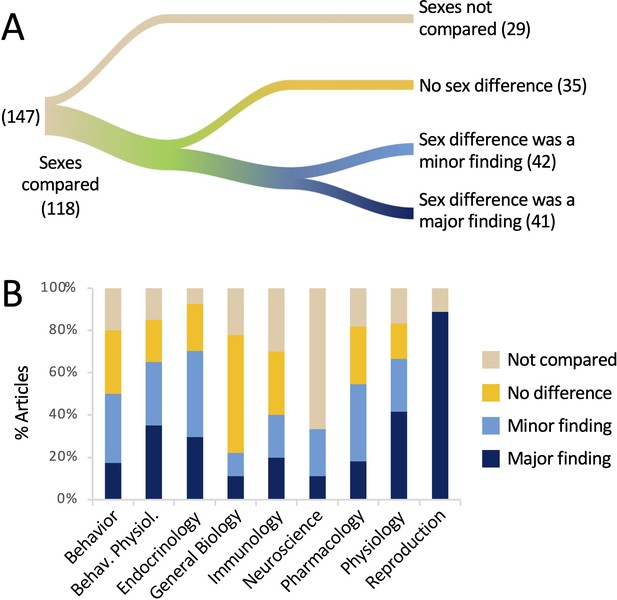
The sexes were compared in the bulk of the articles analyzed.
(A) The river plot shows the proportions of manufactures comparison the sexes, either statistically or qualitatively, and the outcomes of those comparisons. The width of each stream is proportional to the number of articles represented in that stream. The numbers of articles are given in parentheses. If a sex divergence was mentioned in the title or abstract, the article was coded every bit 'major finding'. For a river plot showing how (A) fits into the larger context of the study by Woitowich et al., 2020, please run into Figure i—figure supplement 1. (B) The percentage of manufactures in which sexes were compared is plotted for each subject area. All data are shown in Supplementary file 1 and Figure 1—source information 1.
These results are broken downwards past discipline in Figure 1B. The sexes were almost commonly compared in the field of Endocrinology (93%) and least often in the field of Neuroscience (33%). In the field of Reproduction, the sexes were compared 89% of the time and in 100% of those cases, a sex difference was mentioned in the championship or abstruse. Sex activity differences were least likely to exist emphasized in the title or abstract in the fields of General Biological science and Neuroscience (eleven% each).
Although a sex activity difference was claimed in a bulk of articles (57%), not all of these differences were supported with statistical evidence. In more than a quarter of the manufactures reporting a sex activity difference, or 24/83 articles, the sexes were never actually compared statistically. In these cases, the authors claimed that the sexes responded differentially to a treatment when the consequence of treatment was non statistically compared across sex. This effect is explored in more particular under Question 2, below. Finally, we noted at least five articles in which the authors claimed that there was no sex activity difference, but did not appear to accept tested statistically for one.
Question 2: Did the study accept a factorial design with sexual activity as a factor, and if and so, did the authors test statistically whether the event of other factors depended on sex?
For each article, we asked whether it independent a study with a factorial design in which sex was ane of the factors. This design is common when researchers are interested in testing whether the sexes respond differently to a manipulation such as a drug handling (Figure 2A). Below, we utilise the term 'treatment' to refer to any non-sexual practice cistron in a factorial design. Such factors were not limited to handling, however; they too included variables such as genotype, season, age, exposure to stimuli, etc. Hypothetical results of a study with such a design are shown in Figure 2B. In order to draw a decision about whether responses to treatment differed between females and males, the effect of the treatment must be compared across sex. Although there are several ways of making such a comparison (see Cumming, 2012; Gelman and Stern, 2006), information technology is typically washed by testing for an interaction between sex and treatment. If the interaction is pregnant, then a merits can exist made that the sexes responded differently to the handling. Comparing the treated and control groups within each sex, in other words disaggregating the information by sexual activity and testing for effects of treatment separately in females and males, does not test whether the sexes responded differently; that is, it does not test whether the magnitude of the response differs betwixt females and males (Gelman and Stern, 2006; Makin and Orban de Xivry, 2019; Maney, 2016; Nieuwenhuis et al., 2011; Radke et al., 2021).
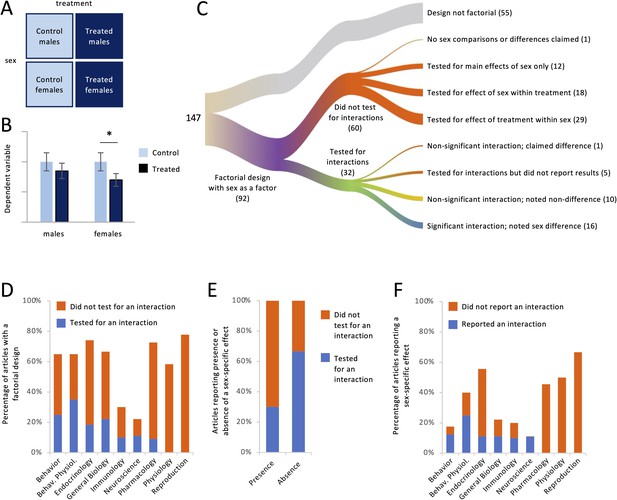
Factorial designs and sex-specific effects.
For each commodity, we noted whether it contained a written report with a factorial design with sex as a factor (A), for case, males and females nested within treated and command groups. (B) In this hypothetical dataset, there was a meaning effect of treatment only in females. Some authors would merits that the treatment had a 'sex-specific' effect without testing statistically whether the response to treatment depended on sexual activity. In this instance, it does non (encounter Maney, 2016; Nieuwenhuis et al., 2011). (C) The river plot shows the proportion of articles with a factorial design and the analysis strategy for those. The width of each stream is proportional to the number of manufactures represented in that stream. The numbers of manufactures are given in parentheses. (D) The percentage of manufactures with a factorial design (meet A) is plotted for each discipline. But a minority tested for an interaction between sex and other factors. (Eastward) Testing for an interaction was less common in articles claiming the presence of a sex-specific effect, meaning a sex deviation in the degree to which a second variable affected the consequence variable, than in articles claiming the absence of such an event. (F) The percentage of manufactures claiming a sex activity-specific outcome is plotted for each subject. Simply a minority reported a significant interaction.
The results pertaining to Question 2 are shown in Figure 2C-F. Out of the 147 articles we analyzed, 92 (63%) contained at least one study with a factorial pattern in which sex activity was a factor (Effigy 2C). Regardless of whether a sex divergence was claimed, we constitute that the authors explicitly tested for interactions between sex and other factors in only 27 of the 92 articles (29%). That is, authors tested statistically for a sexual practice difference in the responses to other factor(south) less than 1-tertiary of the time. Testing for interactions with sex varied by field of study (Figure 2D). Authors were most likely to test for and report the results of interactions in the field of Behavioral Physiology (54% of relevant articles) and least likely in the fields of Physiology (0%) and Reproduction (0%).
Of the studies with a factorial design, 58% reported that the sexes responded differently to one or more other factors. The language used to state these conclusions often included the phrase 'sexual practice difference' but could also include 'sex-specific issue' or that a treatment had an effect 'in males merely not females' or vice versa. Of the 53 articles containing such conclusions, the authors presented statistics showing a significant interaction, in other words advisable evidence that females and males responded differently, in only 16 (thirty%; Effigy 2E, blueish color in first cavalcade). In an additional article, the authors presented statistical evidence that the interaction was non-meaning, yet claimed a sex-specific effect nonetheless. In v other articles, the authors mentioned testing for interactions but presented no results or statistics (e.thou., p values) for those interactions. In the rest of articles containing claims of sexual practice-specific effects, the authors took one of two approaches; neither approach included testing for interactions. Instead, authors proceeded to what would normally be the post hoc tests conducted after finding a significant interaction. In 24 manufactures (45% of articles with claims of sexual practice-specific effects), authors reported the result of treatment inside each sex and, reaching different conclusions for each sexual practice (e.g., finding a p value below 0.05 in one sex only not the other), inappropriately argued that the response to treatment differed betwixt females and males (run into Effigy 2B). In vii other manufactures claiming a sex-specific result (13%), the sexes were compared within treatment; for example, authors compared the treated males with the treated females, not considering the control animals. Neither approach tests whether the treatment had different effects in females and males. Thus, a substantial majority of articles containing claims of sex-specific effects (70%) did not present statistical show to support those claims (Figure 2E, blood-red color in showtime column); further, in the bulk of articles without such evidence (24/37), the sexes were never compared statistically at all.
The omission of tests for interactions was related to whether researchers were challenge sex differences or not. Among the articles that were missing tests for interactions and yet independent conclusions about the presence or absenteeism of sex-specific furnishings (41 manufactures), those claims were in favor of sex activity differences 88% of the time, compared with only 12% claiming that the responses in females and males were similar. Of all of the articles claiming similar responses to treatment, authors tested for interactions in the bulk of cases (67%; Figure 2E bluish color in second column).
The prevalence of reporting sex-specific effects is broken downwardly by bailiwick in Effigy 2F. The field with the lowest percentage of sex activity-specific effects was Behavior (18%), and that field as well had the highest charge per unit of bankroll up such claims with statistical prove (71%). The field most likely to contain claims of sex-specific effects was Reproduction (67%), only this field was among iii for which such claims were never backed upwardly with statistical evidence (0% for Reproduction, Physiology, or Pharmacology).
Question 3: Were the data from males and females pooled for whatever of the analyses?
In this study we included only articles in which data were reported by sexual practice as previously adamant past Woitowich et al., 2020. Thus, whatever manufactures in which the sexes were pooled for all analyses were non included hither. Nosotros assigned each of the 147 manufactures to one of iii categories, as follows (Figure 3A). In 31 (21%) of the manufactures, data from males and females were analyzed separately throughout. In 62 (42%) of the articles, males and females were analyzed in the same statistical models, but in those cases sex was included every bit a fixed gene or a covariate. In most cases when sex activity was a covariate, authors reported the results of the result of sex rather than simply controlling for sexual practice. In the remaining 54 (37%) manufactures, the sexes were pooled for at least some of the analyses.
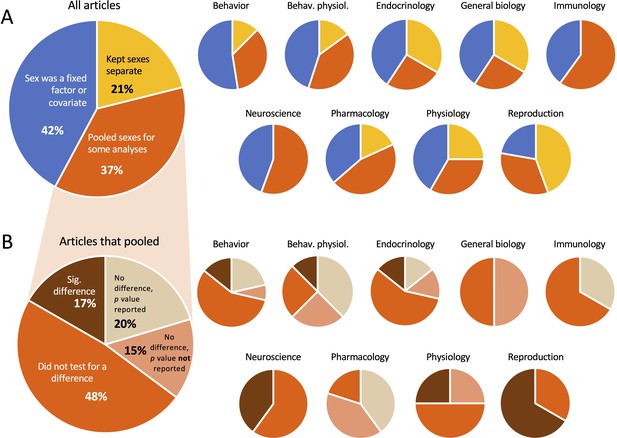
Proportion of manufactures in which the sexes were pooled.
(A) In our sample, roughly one-third of the articles pooled the sexes for at to the lowest degree some analyses. (B) Amid the manufactures that pooled, more than one-half did not test for a sex difference before pooling. In both (A) and (B), the smaller pie charts bear witness the proportions inside subject area. For the data used to brand the charts, see Supplementary file 1c and Figure three—source information 1.
Among the articles in which the sexes were pooled, the authors did and then without testing for a sex deviation nearly one-half of the time (48%; Effigy 3B). When authors did examination for a sex difference before pooling, they sometimes found a significant departure all the same pooled the sexes anyway; this occurred in 17% of the articles that pooled. When the sexes were pooled after finding no significant deviation (35% of the articles that pooled), authors presented p values for the sex difference the majority of the fourth dimension (xi out of nineteen articles). Those p values ranged from 0.15 to >0.999. Nosotros noted no issue sizes reported in the context of pooling.
Across disciplines, pooling was about prevalent in Immunology (60%) and to the lowest degree prevalent in General Biological science (22%). Males and females were virtually likely to be kept split in General Biology (56%) and well-nigh probable to exist included in statistical models in the field of Behavior (53%). When females and males were pooled, authors in the field of Immunology were least likely to have tested for a sex difference earlier pooling (33%) and most likely to do so in Pharmacology (80%). Pooling afterward finding a pregnant difference was most common in the field of Reproduction (67% of manufactures that pooled).
Question 4: Was the term 'gender' used for non-human animals?
To refer to the categorical variable comprising male/female or man/woman (all were binary), the term 'sex' was used exclusively in 69% of the articles (Figure 4). 'Gender' was used exclusively in 9%, and both 'sex activity' and 'gender' were used in nineteen%. When both terms were used, they usually seemed to be used interchangeably. In 4% of the articles, neither term was used.
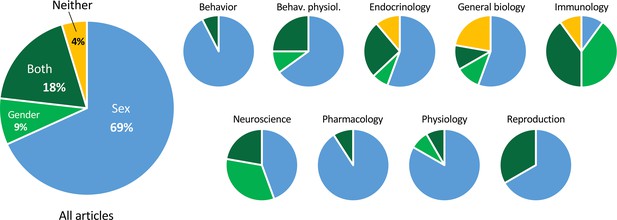
Proportions of manufactures using the terms 'sex' and 'gender'.
The smaller pie charts show the proportions within discipline. The charts include all articles analyzed, on both humans and not-humans. For the data used to brand the charts, come across Supplementary file 1C and Figure iv—source data 1.
Of the articles in which the term 'gender' was used, 20% of the time information technology referred to non-human animals, such as mice, rats, and pigs. In one case, both 'sexual practice' and 'gender' were used to refer to not-human animals in the title. In some other case, 'gender' was used to refer to human cells. The majority of manufactures on non-human species used 'sex' (85%).
Discussion
Finding sexual practice differences
Woitowich et al., 2020, constitute that over the past decade, the proportion of biological studies that included both females and males has increased, but the proportion in which sex is treated as a variable has not. Hither, we have taken a closer look at the studies determined past those authors to have reported data past sex, that is, to have conformed to NIH guidelines on SABV. Nosotros found that in this subset of studies, authors typically also compared the sexes either statistically or by exclamation (>80% of cases). Thus, the authors that complied with NIH guidelines to disaggregate information normally went beyond NIH guidelines to explicitly compare the sexes with each other. This finding is consistent with a larger analysis of articles in the field of Neuroscience from 2010 to 2014; when authors disaggregated data by sex, they usually proceeded to compare the sexes as well (Will et al., 2017). Information technology is of import to note, yet, that both Will et al., 2017, and Woitowich et al., 2020, institute that data were not analyzed by sex in the majority of articles that included both sexes (come across Figure one—effigy supplement 1). Thus, our current finding that the sexes were commonly compared should be interpreted in the context of the subset of articles following NIH guidelines. In the set of articles analyzed here, sex differences were claimed in a bulk and were often highlighted in the championship or abstract. Nosotros therefore institute little bear witness that researchers—at to the lowest degree those who comply with NIH guidelines—are uninterested in sexual activity differences. We cannot dominion out the possibility, notwithstanding, that the researchers following NIH guidelines are primarily those that are interested in sex differences.
Testing for interactions in a factorial pattern
Testing whether the sexes respond differently to a treatment requires statistical comparing between the two furnishings, which is typically done by testing for a sexual practice × treatment interaction. In our analysis, yet, tests for interactions were done only 29% of the time (Figure 2C and D). In the remaining 71%, the most common method for detecting differential furnishings of treatment was to compare qualitatively the conclusions drawn for each sexual practice; that is, to affirm that a p value below 0.05 for one sex only not the other (Effigy 2B) represents a meaningful difference betwixt the effects. Just null hypothesis significance testing does not let for such conclusions (Cumming, 2012). This error, and the frequency with which information technology is made, has been covered in multiple publications; for example Gelman and Stern, 2006, titled their commentary "The deviation between 'significant' and 'not pregnant' is not itself statistically meaning." Makin and Orban de Xivry, 2019, included the error in their 'Top x listing of common statistical mistakes'. In an analysis of 520 articles in the field of Neuroscience, Nieuwenhuis et al., 2011, found that the error was committed in about half of manufactures containing a factorial design. The current analysis showed that, even a decade later, the frequency of this error in the field of Neuroscience has not changed (Effigy 2D), at to the lowest degree when sex is one of the factors nether consideration. The frequency of the fault was loftier in almost of the other disciplines as well, particularly Physiology and Reproduction, for which we found that authors never tested for interactions fifty-fifty though doing so was necessary to test their hypotheses most sexual activity.
Statements such as the following, normally made without statistical evidence, were common: 'The treatment increased expression of factor 10 in a sex-dependent mode'; 'Our results demonstrate that deletion of gene Ten produces a male-specific increase in the behavior'; 'Our findings indicate that females are more than sensitive to the drug than males'. In some of these cases, the terms 'sexual activity-specific', 'sex-dependent', or 'sexual dimorphism' were used in the title of the commodity despite a lack of statistical evidence supporting the claim. In many of these articles, some of which stated that finding a sex difference was the major goal of the study, the sexes were not statistically compared at all. Thus, a lack of statistical evidence for sex-specific effects did not foreclose authors from asserting such effects. Authors failing to test for interactions were far more likely to claim sex-specific effects than not (88% vs. 12%; Supplementary file 1c); they were also more likely to do then than were authors that did test for interactions (88% vs. 63%; Supplementary file 1c). Statistical analysis of these data showed that, in fact, sex-specific effects were reported significantly more often when no tests for interactions were reported (χtwo = 5.84; p = 0.016). Together, these results suggest a bias toward finding sex differences. In the absence of evidence, differences were claimed generally. A bias toward finding sex activity differences, where there are none, could artificially inflate the importance of sex in the reporting of biological data. Given that findings of sex × handling interactions are rare in the human clinical literature, with false positives outnumbering simulated negatives (Wallach et al., 2016), and given also that sex differences are frequently reported in the media and used to shape didactics and health policy (Maney, 2014), it is especially important to base conclusions from preclinical research on solid statistical prove.
Pooling across sex
The gear up of manufactures nosotros analyzed was pre-screened by Woitowich et al., 2020, to include only studies in which sexual practice was considered as a variable. Yet, fifty-fifty in this sample, data were often pooled beyond sexual practice for some of the analyses (Figure 3A). In a bulk of these articles, authors did not examination for a sex difference before pooling (Figure 3B). Thus, for at least some analyses represented hither, the data were not disaggregated by sex, sex was not a factor in those analyses, and we do non know whether in that location might accept been a sexual activity difference. Even when authors did examination for a sex difference before pooling, the relevant statistics were often non presented. Finding and reporting a pregnant sex difference did not seem to reduce the likelihood that the sexes would be pooled. Note that the original sample of 720 articles in the study by Woitowich et al. included 251 articles in which sex was either not specified or the sexes were pooled for all analyses (Figure i—effigy supplement 1). Thus, the effect is more than widespread than is represented in the current report. Pooling is not consistent with the NIH mandate to disaggregate information by sex and can prevent detection of meaningful differences. We notation farther that outcome sizes were generally not reported earlier pooling; in add-on to p values, event sizes would exist valuable for whatever assessment of whether data from males and females can be pooled without masking a potentially important difference (Beltz et al., 2019; Diester et al., 2019).
Correcting for multiple comparisons
In their article on '10 statistical mistakes…,' Makin and Orban de Xivry, 2019, list another event that is likely to exist relevant to the report of sex differences: comparing multiple dependent variables beyond sex without correcting for multiple comparisons. The omission of such a correction increases the risk of false positives, that is, making a blazon I error, which would result in over-reporting of significant furnishings. This hazard is particularly important for researchers trying to comply with SABV, who may feel compelled to test for sex activity differences in every measured variable. In the electric current study, we institute this issue to be prevalent. For example, we noted articles in which researchers measured expression of multiple genes in multiple tissues at multiple time points, resulting in a large number of comparisons beyond sex. In ane such written report, authors fabricated 90 carve up comparisons in the aforementioned set of animals and institute five significant differences, which is exactly the number one would look to observe by take a chance. Although opinions vary about when corrections are necessary, omitting them when they are clearly needed is probable contributing to over-reporting of sex differences broadly beyond disciplines.
Usage of 'sex activity' and 'gender'
We found that a large majority of studies on not-human animals used 'sex activity' to refer to the categorical variable comprising females and males. In 8 articles, we noted usage of the word 'gender' for not-human being animals. This usage appears to conflict with current recommendations regarding usage of 'gender', that is, gender should refer to socially constructed identities or behaviors rather than biological attributes (Clayton and Tannenbaum, 2016; Holmes and Monks, 2019; Woitowich and Woodruff, 2019). We did not, all the same, investigate the authors' intended meaning of either term. Although definitions of 'gender' vary, the term might exist appropriate for not-human animals under sure circumstances, such as when the influence of social interactions is a main bespeak of interest (Cortes et al., 2019). Operational definitions, even for the term 'sex', are important and, in our feel conducting this study, almost never included in publications. Equally others have done (east.yard., Duchesne et al., 2020; Cortes et al., 2019; Holmes and Monks, 2019; Johnson et al., 2009), we emphasize the importance of clear operational definitions while recognizing the limitations of binary categories.
Limitations of this study
The categorization of each article into a detail discipline was defined exclusively by the periodical in which it appeared, in guild to be consistent with the original categorizations of Beery and Zucker, 2011, and Woitowich et al., 2020. For virtually disciplines, fewer than a dozen articles were in our starting sample; for Neuroscience and Reproduction, only nine. As a upshot, after nosotros coded the articles, some categories independent few or no manufactures in a given discipline (encounter Supplementary file 1c). The inside-discipline analyses, particularly the pie charts in Effigy 3B, should therefore be interpreted with caution. Firm conclusions about whether a particular practice is more prevalent in one discipline than another cannot exist drawn from the data presented here.
As is the case for any assay, qualitative or otherwise, our coding was based on our interpretation of the data presentation and diction in the articles. Details of the statistical approach were sometimes left out, leaving the author'due south intentions ambiguous. Although our approach was every bit systematic as possible, a small number of articles may have been coded in a way that did not completely capture those intentions. Nosotros believe our sample size, particularly in the overall analyses beyond disciplines, was sufficient to reveal the important trends.
Decision
SABV has been hailed as a game-changing policy that is already bringing previously ignored sex-specific factors to lite, particularly for females. In this study, we accept shown that a substantial proportion of claimed sex differences, particularly sex-specific furnishings of experimental manipulations, are non supported past sufficient statistical evidence. Although only a minority of studies that include both sexes actually report information past sexual practice (Woitowich et al., 2020), our findings suggest that when data are reported by sexual practice, disquisitional statistical analyses are often missing and the findings likely to exist interpreted in misleading ways. Annotation that in most cases, our findings do not indicate that the conclusions were inaccurate; they may have been supported past advisable statistical analyses. Our results emphasize the need for resource and preparation, particularly those relevant to the report designs and analyses that are commonly used to discover sexual practice differences. Such training would benefit not only the researchers doing the piece of work, but as well the peer reviewers, journal editors, and program officers who have the ability to concord researchers to a higher standard. Without better awareness of what can and cannot be ended from dissever assay of males and females, SABV may have the undesired upshot of reducing, rather than enhancing, rigor and reproducibility.
Materials and methods
We conducted our analysis using journal manufactures from a list published by Woitowich et al., 2020. In their study, which was itself based on a study by Beery and Zucker, 2011, the authors selected 720 articles from 34 journals in nine biological disciplines. The disciplines were defined by Beery and Zucker and were each represented by four journals, with the exception of Reproduction, which was represented by ii (Table ane). To be included, articles needed to exist primary research articles not part of a special issue, describe studies conducted on mammals, and be published in English. For each journal, Woitowich et al. selected the first xx manufactures meeting these criteria published in 2019 (xl articles for Reproduction). For most disciplines, all articles were published between Jan and April, 2019; for others, manufactures could take been published as late as June, Baronial, or Oct for Endocrinology, Behavioral Physiology, and Behavior, respectively.
Woitowich et al., 2020, coded each commodity with respect to whether information technology contained data analyzed by sex, defined every bit either that the sexes were kept separate throughout the analysis or that sex was included as a fixed factor or covariate. Of the original 720 manufactures analyzed, 151 met this criterion. We began our written report with this list of 151 manufactures. Four manufactures were excluded considering they contained data from only one sex, with animals of the other sex used as stimulus animals or to calculate sexual activity ratios.
Our coding strategy was collaborative (Saldana, 2021). The majority of the articles (n = 131 out of 151) were read by the first author (YGS) to ascertain the bones experimental designs in the dataset. A subset of the articles (northward = 34), spanning a diversity of designs, was and so discussed between the authors to develop an analysis strategy. This strategy consisted of determination trees used to assign manufactures to hierarchical categories pertaining to each of 4 central questions (see below). Once the authors agreed on a set of categories that would effectively capture the variables of interest, the second author (DLM) coded all of the articles, assigning each to one category per question. During coding, manufactures for which the most advisable category was non immediately obvious were discussed between the authors until agreement was reached. This process resulted in the modification of some of the categories, which improved conceptual clarity and strengthened the analysis. Once the decision tree was finalized (Supplementary file 1a) and all articles were coded accordingly, the first writer then independently coded 3 manufactures from each subject area to appraise reliability of the method (Q1-Q4 for each of 27 articles). Interrater reliability, calculated as the number of agreements divided by the number of agreements plus disagreements, was 93%. During the subsequent give-and-take, the categorization was changed to that of the first writer for approximately one-half of the discrepancies (three% of the total number of decisions); the other 3% remained the same. The final categorizations in Supplementary file 1b represent consensus between the authors subsequently all readings and discussions.
Question ane: Was a sex difference reported?
Request a detailed protocolBecause we were interested in the frequency with which sexual practice differences were found, we first identified articles in which the sexes were explicitly compared. We counted as a comparison any of the following: (1) sexual activity was a fixed factor in a statistical model; (2) sexual practice was included every bit a covariate in a statistical model and a p value for the effect of sexual activity was reported; (3) a p value for a comparison of means between males and females was presented; (iv) the commodity contained diction suggestive of a comparison, for example, 'males were larger than females'. We also included articles with wording suggestive of a sex difference in response to a treatment, for example, 'the treatment affected males just not females' or 'the males responded to treatment, whereas the females did not', or 'the treatment had a sexual practice-specific effect'. Similarly, we included here manufactures with language referring to a not-difference, for instance, 'we detected no sex differences in size' or 'the response to treatment was similar in males and females'. Articles in which sex was included equally a covariate for the purposes of controlling for sex, rather than comparing the sexes, were not coded as having compared the sexes (run across Beltz et al., 2019). When the sexes were compared merely no results of those comparisons, for example, p values, were reported, that omission was noted and the article was coded accordingly. Each article in which the sexes were compared was then further coded as either reporting a sex difference or not, and if so, whether a sex difference was mentioned in the title or abstract. If mentioned in the title or abstract, the sex activity difference was coded as a 'major finding'; otherwise, sex activity differences mentioned in the body of the paper, figures, or tables were coded equally 'minor'.
Question 2: Did the article incorporate a report with a factorial design?
Asking a detailed protocolNosotros looked for studies with a ii × 2 factorial design (Effigy 2A) in which sex activity was one of the factors. Sexual practice did non demand to be explicitly identified as a fixed cistron; we included here all studies comparing across levels of i factor that comprised females and males with each of those levels. In some cases that factor was a manipulation, such every bit a drug treatment or a gene knockout. Non-sexual activity factors also included variables such as age, season, presentation of a stimulus, etc. For simplicity, we refer to the other factor as 'treatment'. Any commodity containing at to the lowest degree one such study was coded as having a factorial design. The other articles were coded as containing no comparisons across sexual activity or as containing only group comparisons across sex activity. The latter category included studies with sex as a covariate of interest in a model such as a multiple regression, if the authors were non making any claims about potential interactions between sexual practice and other variables.
For studies with a factorial blueprint, we farther coded the authors' strategy of data analysis. First, nosotros noted whether authors tested for an interaction betwixt sexual activity and treatment; that is, they tested whether the effect of treatment depended on sexual activity. We coded every bit 'yes' one study in which the magnitude of the differences betwixt treated and control groups was explicitly compared beyond sex. For articles containing tests for interactions, we noted the event of that test and the estimation. Articles containing no tests for interactions were assigned to i of several sub-categories in the following lodge (coded as the commencement category on this listing for which the description was met for whatsoever assay in the article): tested for effects of handling within sexual practice, tested for effects of sex within at least one level of treatment, or tested for main effects of sexual activity merely. Within each of those categories we farther coded the upshot/interpretation, for instance, sex deviation or no sex difference. Any articles containing statements that the sexes responded differently to treatment or that the response was 'sex-specific' were coded as reporting a sex-specific result. We also noted when authors reported an absence of such a result. Articles non comparing across sex at all, with statistical evidence or by assertion, were coded accordingly.
Question 3: Did the authors puddle males and females?
Request a detailed protocolNosotros assigned articles to one of three categories: analyzed males and females separately throughout, included sex in the statistical model for at to the lowest degree some analyses (with the rest analyzed separately), or pooled for at least some analyses. The second category, included sex in the model, included articles in which AIC or like statistic was used to cull among models that included sexual practice, although sex may not have been in the model ultimately called. This category did not distinguish between analyses including sex as a stock-still factor vs. a covariate; this distinction is noted where relevant in Supplementary file 1b. Whatever commodity containing pooled data was coded as pooled, even if some analyses were conducted separately or with sex in the model. For articles that pooled, we further noted whether the authors tested for a sex difference earlier pooling and, if so, whether p values or effect sizes were reported.
Question iv: Did the authors employ the term 'sex' or 'gender'?
Request a detailed protocolWe searched the articles for the terms 'sexual practice' and 'gender' and noted whether the authors used i or the other, both, or neither. Terms such every bit 'sex activity hormones' or 'gender role', which did non refer to sex/gender variables in the study, were excluded from this cess. For the articles using 'gender', we further noted when the term was used for non-human animals.
To visualize the data, we used river plots (Weiner, 2017), stacked bar graphs, and pie charts based on formulae and data presented in Supplementary file 1c.
Data availability
All data generated or analysed during this written report are included in the manuscript and supporting files.
References
-
Book
Understanding the New Statistics: Effect Sizes, Confidence Intervals, and Meta-Analyses
New York, NY: Routledge.
- Google Scholar
Decision letter
Decision letter of the alphabet after peer review:
Thanks for submitting your commodity "Reporting and Misreporting of Sex Differences in the Biological Sciences" for consideration past eLife. Your article has been reviewed past 3 peer reviewers, and the evaluation has been overseen by a Reviewing Editor and Mone Zaidi every bit the Senior Editor. The post-obit individuals involved in review of your submission accept agreed to reveal their identity: Colby J Vorland (Reviewer #1); Chanaka Kahathuduwa (Reviewer #3).
The reviewers take discussed their reviews with one some other, and the Reviewing Editor has drafted this to help you prepare a revised submission.
Reviewer #one (Recommendations for the authors):
Regarding the coding of papers, additional details almost the subset of articles independently coded would exist helpful to assess how you are confidence in the extraction quality.
Give thanks yous for providing your information forth with the manuscript. I have no further comments separate from my public review.
Reviewer #ii (Recommendations for the authors):
It seems similar a severe omission in the introduction to not include and discuss the NIH'due south own retrospective on their requirement:
Arnegard, Yard. E., Whitten, 50. A., Hunter, C., and Clayton, J. A. (2020). Sexual activity as a Biological Variable: A 5-Year Progress Report and Telephone call to Action. Journal of women's health (2002), 29(6), 858-864. https://doi.org/10.1089/jwh.2019.8247
The operationalization of a "major finding" is not defined in the text, only cached in a effigy explanation.
River plots should have counts/percentages included with them.
Effigy 1B – Why are the percentages non out of 100%? If the remainders are "Sexes not compared" then that should exist included as a fourth category in the plot.
Figures 2nd-F – Same concern every bit with 1B.
The difference betwixt Figures 2D and 2E is non well explained.
"We found that a big majority of studies on not-man animals used "sexual practice" to refer to the chiselled variable comprising females and males (Figure 4)." Are the counts in Effigy iv for the subset of not-human studies? The description in the Results section and figure caption exercise not mention that earlier.
"…we accept shown that a substantial proportion of claimed sex differences, particularly sex-specific furnishings of experimental manipulations, are non supported by statistical evidence." This refers to my earlier comment. Ironically given the bailiwick affair, I don't feel similar a single proportion was given to this characterization of manufactures.
Reviewer #3 (Recommendations for the authors):
1. Delight describe the methods used to allocate the articles past subject field. If this method was not objective, consider discussing that equally a limitation.
2. The studies were coded only by i author (author two) and this may compromise the validity of the findings. To mitigate this limitation, a second coder could charge per unit all the studies (or at least a random sample of the studies) using the same criteria and the inter-rater reliability could be presented. If this is not possible, the impact of this major limitation on the conclusions needs to be discussed in the manuscript.
3. Please consider revising the following statements:
a. "our finding could betoken that researchers interested in sex differences are primarily the ones following NIH guidelines." – this statement is not supported by the information.
b. "The prevalence of this issue is difficult to estimate because opinions vary about when corrections are necessary" (regarding correcting for multiple comparisons) – the prevalence of the trouble could be objectively estimated irrespective of one's opinion well-nigh the need to adjust to conserve FWER.
c. "This study was underpowered for examining these issues within any item field of study" – since statistical tests were non performed, it is all-time to avert the term "underpowered".
4. Delight consider presenting the proportions and / or percentages in the river plots. This will substantially facilitate comprehension of the results.
v. Delight consider reporting the reference of each article in Tabular array S2 to enhance transparency and reproducibility. It is not possible to rails most of the reviewed articles using the information presented in the manuscript or the supplementary material.
https://doi.org/10.7554/eLife.70817.sa1
Writer response
The reviewers have discussed their reviews with one some other, and the Reviewing Editor has drafted this to aid you set up a revised submission.
Reviewer #1 (Recommendations for the authors):
Regarding the coding of papers, additional details nearly the subset of articles independently coded would exist helpful to assess how y'all are confidence in the extraction quality.
Nosotros have expanded our description of how coding was handled betwixt the 2 authors. Interrater reliability is now presented and was higher up ninety%.
Cheers for providing your data forth with the manuscript. I have no further comments separate from my public review.
Reviewer #2 (Recommendations for the authors):
Information technology seems like a severe omission in the introduction to non include and discuss the NIH'southward own retrospective on their requirement:
Arnegard, M. E., Whitten, 50. A., Hunter, C., and Clayton, J. A. (2020). Sex as a Biological Variable: A v-Year Progress Written report and Phone call to Action. Periodical of women's health (2002), 29(half dozen), 858-864. https://doi.org/ten.1089/jwh.2019.8247
This article is now cited and a few of its major points are covered in the first paragraph of the manuscript.
The operationalization of a "major finding" is not defined in the text, merely buried in a effigy caption.
Major vs. minor finding was defined in the first paragraph under "Question i" (formerly lines 88-91). The relevant sections of the Results and Methods have been rewritten so that this definition is more than explicitly stated.
River plots should take counts/percentages included with them.
The counts take been added to both river plots.
Figure 1B – Why are the percentages not out of 100%? If the remainders are "Sexes not compared" and then that should be included equally a fourth category in the plot.
"Sexes not compared" has been added to Figure 1B to bring the totals in each column up to 100%.
Figures 2nd-F – Aforementioned business organisation as with 1B.
Figure 2E (formerly 2F) already goes to 100% in both columns. Figures second and 2F (formerly 2E) plot the percentages of papers with a factorial blueprint and the percentages making claims of a sex-specific-outcome, respectively. The latter two categories are so broken downward into whether the authors tested for or reported an interaction, which tin can exist done only for the articles that are actually in the graph. Information technology would non exist appropriate, for example, to examination for an interaction when the design is non factorial, so those papers do not appear in Figure 2nd.
The deviation between Figures second and 2E is not well explained.
We have clarified in the figure caption what is shown in each panel. We have also swapped the club of Figures 2E and 2F, since 2D was more closely related to what is now 2E.
"Nosotros establish that a large majority of studies on non-human animals used "sex" to refer to the chiselled variable comprising females and males (Figure iv)." Are the counts in Figure 4 for the subset of not-human studies? The description in the Results section and figure caption practice not mention that before.
The counts in Figure 4 pertain to all 151 of the papers in the study, not just the not-man ones. This has been antiseptic in the caption. The reference to Figure 4 has been deleted in the sentence the reviewer is referring to – we thank the reviewer for pointing out that the figure did non comprise information relevant to the signal existence made there. We have added to the Results the proportion of manufactures on non-humans that used "sex".
"…we take shown that a substantial proportion of claimed sex differences, particularly sex-specific effects of experimental manipulations, are not supported by statistical show." This refers to my earlier comment. Ironically given the subject thing, I don't feel like a unmarried proportion was given to this characterization of articles.
The reviewer is asking for ii different statistics. Starting time, they pointed out above that we "did not written report overall percentages of articles that "did information technology right" (due east.yard., the original authors appropriately reported on and correctly interpreted the results of an interaction)." This statistic, in other words the proportion of manufactures that did it right, was originally reported in the first paragraph most Question 2 in the Results. A judgement has been added to reiterate and clarify this statement. The same point was also in the Discussion, although there we gave but the percent that did information technology "wrong". The number that did information technology correct (% wrong subtracted from 1) is now also included there.
Second, the reviewer wants to know, out of the studies that claimed sex-specific effects, what proportion actually showed statistical bear witness for such effects. This statistic was given in Figure 2F (now Figure 2E), the get-go column, which shows that ~30% of the articles reporting sex-specific furnishings tested for such. The statistic was also given in the text, under Question 2. References to the relevant effigy have been added to these sentences.
Reviewer #3 (Recommendations for the authors):
1. Please describe the methods used to classify the articles by discipline. If this method was not objective, consider discussing that as a limitation.
Articles were categorized according to the journal in which they appeared. We followed the categorization used by Beery et al., (2011) and Woitowich et al., (2020) for the sake of consistency with those studies. This has been clarified in Tabular array 1 and in the Methods.
2. The studies were coded merely by ane author (author 2) and this may compromise the validity of the findings. To mitigate this limitation, a second coder could charge per unit all the studies (or at to the lowest degree a random sample of the studies) using the same criteria and the inter-rater reliability could exist presented. If this is not possible, the impact of this major limitation on the conclusions needs to be discussed in the manuscript.
As noted above in our response to R1, we have expanded our description in the Methods of how coding was handled among the 2 reviewers and how we are confident in each decision. We have calculated interrater reliability every bit greater than 90%.
three. Delight consider revising the following statements:
a. "our finding could indicate that researchers interested in sex differences are primarily the ones following NIH guidelines." – this argument is not supported past the information.
Nosotros found that in the subset of studies in which data were disaggregated, in other words
NIH guidelines were followed, the sexes were unremarkably as well compared. In that location are 2
possible explanations for this finding – first, researchers who follow NIH guidelines went a pace beyond to compare the sexes; second, that researchers interested in sex
differences are primarily the ones post-obit the guidelines. These are slightly dissimilar
conclusions and our information practise not distinguish betwixt them. Nosotros accept rephrased this
argument so that we do not claim that our data led us to whatever particular conclusion.
b. "The prevalence of this issue is difficult to estimate because opinions vary about when corrections are necessary" (regarding correcting for multiple comparisons) – the prevalence of the problem could be considerately estimated irrespective of ane'south opinion most the need to adjust to conserve FWER.
Any estimation of the prevalence of an mistake requires a clear definition of the fault. Without such a definition, it is not possible to categorize articles as having committed vs. not committed the error. In this case, the weather under which corrections are necessary, and the blazon of correction that is needed, are extremely variable. For instance, some researchers argue that a correction is necessary even when sex is included in an omnibus exam; others argue that the bus test itself obviates the need for corrections. Some researchers argue that corrections are necessary when multiple tests are washed in the same set of animals, others insist that the correction must exist practical to all experiments in the aforementioned manuscript even when separate samples are analyzed. Some point out that in lodge to implement a correction logically and consistently it must be applied over all studies for a PI's unabridged career, and so it is therefore overkill in all cases and should never be done. Equally we do not wish to claim authority regarding what is acceptable or not in this particular area, we decided not to categorize articles co-ordinate to whether they corrected for multiple comparisons in an acceptable way. Instead, we mention in the Word a few extreme cases in order to phone call attending to the outcome. The judgement the reviewer referred to has been omitted in the revision.
c. "This study was underpowered for examining these issues within any particular discipline" – since statistical tests were not performed, it is best to avoid the term "underpowered".
This sentence has been removed.
four. Please consider presenting the proportions and / or percentages in the river plots. This will substantially facilitate comprehension of the results.
The counts take been added to both river plots.
5. Please consider reporting the reference of each article in Table S2 to raise transparency and reproducibility. It is non possible to track most of the reviewed articles using the information presented in the manuscript or the supplementary material.
A column has been added to the table for the title of the article, to follow the precedent gear up by Woitowich et al. (2020).
https://doi.org/10.7554/eLife.70817.sa2
Article and author information
Author details
-
Yesenia Garcia-Sifuentes

-
Donna L Maney
Funding
Emory University Enquiry Committee (00106050 - URC 2021-22)
- Donna L Maney
The funders had no role in written report design, data collection and estimation, or the decision to submit the work for publication.
Acknowledgements
We thank Nicole Baran, Isabel Fraccaroli, and Naomi Greenish for aid and suggestions in the initial stages of this project, and Chris Goode for assistance with the river plots. We are grateful to Lise Eliot, Chris Goode, Niki Woitowich, Colby Vorland, Chanaka Kahathuduwa, and an anonymous reviewer for providing comments on the manuscript.
Senior Editor
- Mone Zaidi, Icahn School of Medicine at Mount Sinai, Usa
Reviewing Editor
- David B Allison, Indiana University, United States
Reviewers
- Colby J Vorland, Indiana University, United States
- Chanaka Kahathuduwa
Publication history
- Received: May 29, 2021
- Preprint posted: May 31, 2021 (view preprint)
- Accepted: September 16, 2021
- Version of Tape published: November 2, 2021 (version 1)
Copyright
© 2021, Garcia-Sifuentes and Maney
This commodity is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted employ and redistribution provided that the original writer and source are credited.
Metrics
-
- 5,452
- Page views
-
- 420
- Downloads
-
- 12
- Citations
Article citation count generated by polling the highest count across the following sources: Crossref, PubMed Central, Scopus.
Download links
A ii-function list of links to download the commodity, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Download citations (links to download the citations from this article in formats compatible with various reference manager tools)
Open citations (links to open the citations from this article in various online reference director services)
Source: https://elifesciences.org/articles/70817
0 Response to "Peer Reviewed Studies on the Differences Between the Sexes"
Post a Comment